
Posted On : 04 March 2020
What is a robots.txt File?

A robots.txt file aka robots exclusion protocol or standard, is a tiny text file, which exists in every website. Designed to work with search engines, it’s been moulded into a SEO boost waiting to be availed. robots.txt file acts as a guideline for the search engine crawlers, as to what pages/files or folders can be crawled and which ones they cannot.
To view a robtots.txt file simply type in the root domain and then add /robots.txt to the end of the URL.
Why a robots.txt is Important for Your Website?
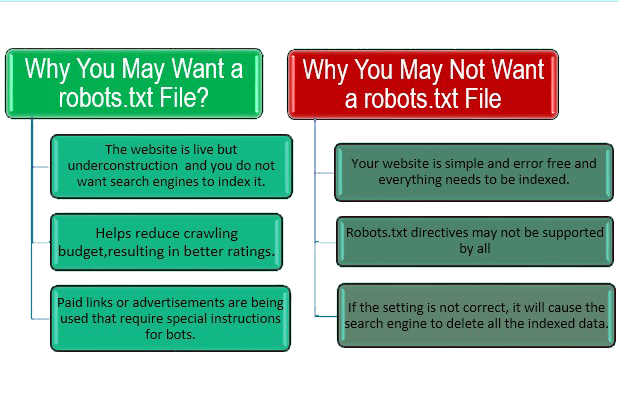
- It helps prevent crawling of duplicate pages by search engine bots.
- It helps in keeping parts of the website private (i.e. not to show in Search Results).
- Using robots.txt prevents server overloading.
- It helps prevent wastage of Google’s “crawl budget."
How to Find Your robots.txt File?
- If a robots.txt file has already been created then it can be accessed through
www.example.com/robots.txt
How to Create a robots.txt File?
- In order to create a new robots.txt file one needs to open a blank “.txt” document and commence writing directives.
- For example, if you want to disallow all search engines from crawling your /admin/ directory, it should look similar to this:
User agent : *
disallow: /admin/
Where to Save Your robots.txt File?
- The robots.txt file needs to be uploaded in the root directory of the main domain to which it is applied to.
- In order to control crawling behaviour on www.bthrust.com, the robots.txt file should be accessible from.
Basic Format of robots.txt
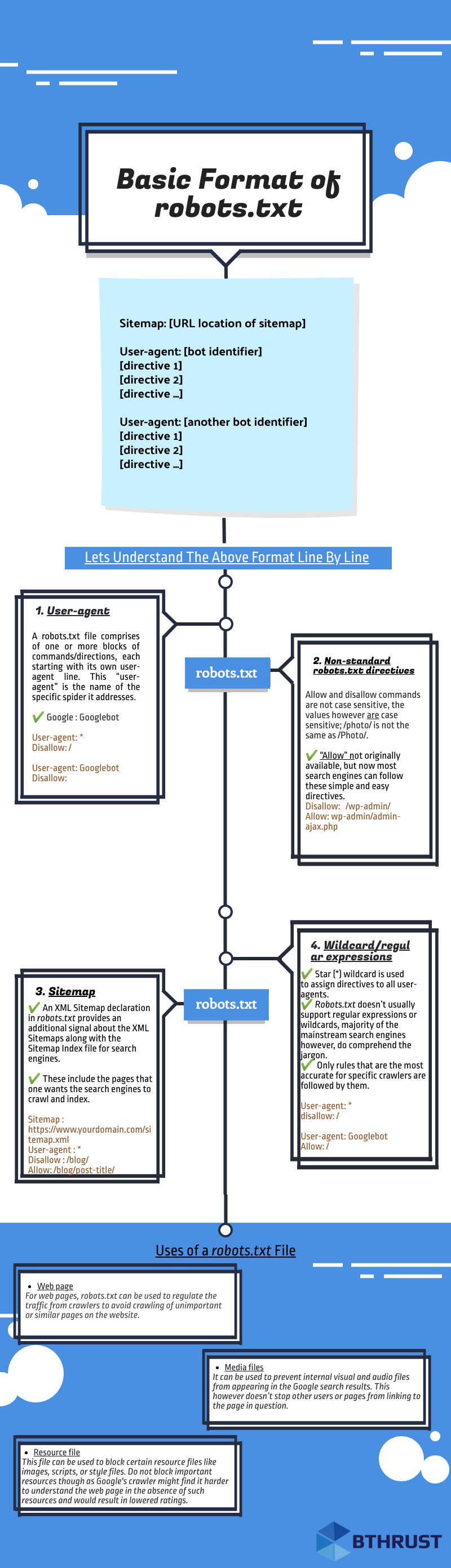
Lets Understand the robots.txt Format Line by Line
1. User-agent
- A robots.txt file comprises of one or more blocks of commands or directives, each starting with its own user-agent line. This “user-agent” is the name of the specific spider it addresses. A search engine spider will always pick the block that best matches its name.
- There are various user-agents but the most prominent ones for SEO are-
1. Google: Googlebot
2. Bing: Bingbot
3. Baidu: Baiduspider
4. Google Image: Googlebot-Image
5. Yahoo: Slurp
Note: It’s highly important for us to know that user-agents are case sensitive in robots.txt. Following example is incorrect because Google’s user-agent is “Googlebot” not “googlebot”
User-agent: googlebot
Disallow:
The correct example would be:
User-agent: Googlebot
Disallow:
2. Sitemap Directive
- This directive is used to specify the location of your sitemap(s) for the search engines.
- An XML Sitemap declaration in robots.txt provides a supplementary signal regarding the presence of XML Sitemaps for search engines.
- Sitemap includes the pages you want the search engines to crawl and index. The code should look like this:
Sitemap : https://www.example.com/sitemap.xml - The sitemap tells the search engine crawlers how many pages are there to be crawled, when the page was last modified, what of pages, and how often is the page likely to be updated.
- The sitemap directive does not need to be repeated or duplicated multiple times for each and every user-agent. It is applicable to all.
- It is optimum to include sitemap directives either at the start or towards the end of the robots.txt file.
A code with sitemap directive in the beginning should look like:Sitemap : https://www.example.com/sitemap.xml
User-agent: Googlebot
Disallow: /blog/
Allow: /blog/post-title/
A code with sitemap directive in the end should look like:User-agent: Googlebot
Disallow: /blog/
Allow: /blog/post-title/
Sitemap : https://www.example.com/sitemap.xml
3. Wildcard/Regular Expressions
- Star (*) wildcard is used assign directives to all user-agents.
- Every time a new user-agent is declared, that acts like a clean slate. Essentially, the directives declared initially for the first user-agent do not apply to the second, or third and so on.
- Only rules that are the most accurate for specific crawlers are followed by the crawler’s name.
User-agent: Googlebot
Allow: /
The above rule blocks all bots except Googlebot from crawling the site.
4. Some Starter Tips:
- Each and every directive should start from a new line.
Incorrect
User-agent : * Disallow: /directory/ Disallow: /another-directory/Correct User-agent : *
Disallow: /directory/
Disallow: /another directory/ - Wildcards (*) can be used to apply directives to user-agents as well as to match URL patterns when declaring the said directives.
User-agent: *This however is not that effective and it’s best to keep the wildcard as simple as possible. as shown below to block all files and pages in /products/ directory
Disallow: /products/it-solutions
Disallow: /products/seo-solutions
Disallow: /products/graphic-solutions
User-agent: *
disallow: /products/ - Always use $ sign to specify the end of the URL path, In order to allow or disallow content like PDF etc to the search engine.
User agent: *
Allow: /*.pdf$
Disallow: /*.jpg$
- Each user agent command should be used one time only. As all Search Engines simply compile all the prior mentioned rules into one and follow all of them. As shown below.
User agent: BingbotAbove code should be written as follows
Disallow: /a/
User agent: Bingbot
Disallow: /b/User agent: BingbotGoogle will not crawl any of these folders but it is still far more beneficial to be direct and concise. Chances of mistakes and errors are also reduced when there are lesser commands to code and follow.
Disallow: /a/
Disallow: /b/ - In case of a missing robots.txt file, search engine crawlers crawl through all the publicly available pages of the website and add it to their index.
- If an URL is neither disallowed in robots.txt nor it is in XML sitemap, it can be indexed by search engines unless a robot meta tag of noindex is implemented in that page.
- If search engines cannot understand the directives of a file due to any reason, bots can still access the website and disregard the directives that are in the robots.txt file.
- Use separate robots.txt file for every domain and sub-domain, like for www.example.com and blog.example.com , even if the main domain is same.
- Use single robots.txt file for all subdirectories under single domain.
5. Non-Standard robots.txt Directives
- Allow and Disallow commands are not case sensitive, the values however are case sensitive. As shown below /photo/ is not same as /Photo/, but Disallow is same as disallow
- There can be more than one Disallow directive, specifying which segments of the website the spider cannot access.
- An empty Disallow directive allows the spider to have access to all segments of the website as it essentially means nothing is being disallowed and the command would look like:
User –agent: *
Disallow:
- Block all search engines that listen to robots.txt from crawling your site and the command would look like:
User –agent: *
Disallow: / - “Allow” not originally available, but now most search engines can follow these simple and easy directives to allow one page inside a disallowed directory.
Disallow: /wp-admin/
Allow: wp-admin/admin-ajax.php - If not for “Allow” directive, one would have to categorically disallow files and that is a tedious task.
- One has to give concise “allow” & “disallow” commands otherwise there might be a conflict between the two.
User-agent: *
Disallow: /blog/
Allow: /blogIn Google and Bing, the directive with the most characters is followed.
Bthrust.com Example
User-agent: *
Disallow: /blog/
Allow: /blogBy above code, bthrust.com/blog/ and pages in the blog folder will be disallowed in spite of an allow directive(5 characters) for such pages because disallow directive have longer path value((6 characters)).
Most Commonly Used robots.txt Commands
- No access for all crawlers
User-agent : *
Disallow: / - All access for all crawlers
User-agent : *
Disallow: - Block one sub directory for all crawlers
User-agent : *
Disallow: /folder/ - Block one sub directory for all crawlers with only one file allowed
User-agent : *
Disallow:/folder/
Allow: /folder/page.html - Block one file for all crawlers
User-agent : *
Disallow: /this-file-is-not-for-you.pdf - Block one file type for all crawlers
User-agent : *
Disallow: /*.pdf$
Uses of a robots.txt File
| Page Type | Description |
|---|---|
|
Web page |
For web pages, robots.txt can be used to regulate crawling traffic to avoid crawling of unimportant or similar pages on the website. |
| robots.txt should not be used to hide web pages from Google, as other pages can point to the hidden web page with descriptive text, and the page would be indexed without visiting the page. | |
|
Media files |
robots.txt can be used to manage crawl traffic, and to prevent visual and audio files from appearing in the Google search results. This however doesn’t stop other users or pages from linking to the page in question. |
|
Resource file |
robots.txt can be used to block resource files like certain images, scripts, or style files. Google's crawler might find it harder to understand the web page in the absence of such resources and would result in lowered ratings. |
Why Your WordPress Needs a robots.txt File
Every search engine bot has a maximum crawl limit for each website i.e. X number of pages to be crawled in a crawl session. If let’s say the bot in unable to go through all the pages on a website, it will return back and continue crawling on in the next session and that hampers your website’s rankings.
This can be fixed by disallowing search bots to crawl unnecessary pages like the admin pages, private data etc.
Disallowing unnecessary pages obviously saves the crawl quota for the site and that in turn helps the search engines to crawl more pages on a site and index faster than before.
A default WordPress robots.txt should look like this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
The WordPress website creates a virtual robots.txt file when the website is created in the server’s main folder.
Thisismywebsite.com -> website
Thisismywebsite.com/robots.txt -> to access robots.txt file
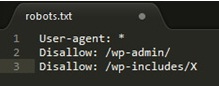
A code similar to this should be observed, it’s a very basic robots.txt file
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Allow: /wp-admin/admin-ajax.php
In order to add more rules, one needs to create a new text file with the name as “robots.txt” and upload it as the previous virtual files replacement. This can simply be done in any writing software as long as the format remains in .txt.
Creating a New WordPress robots.txt File:
Below we explained 3 methods of implementing robots.txt
Method 1: Yoast SEO
The most popular SEO plug-in for WordPress is Yoast SEO, due to its ease of use and performance.
Yoast SEO allows the optimization of our posts and pages to ensure the best usage of our keywords.
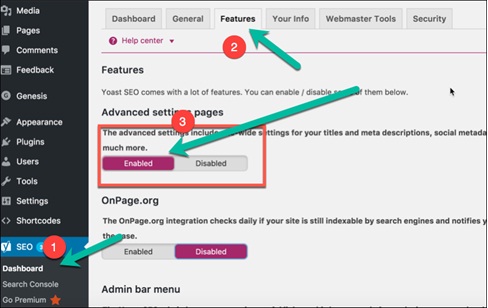
It’s Doable in 3 Simple StepsStep 1. Enable advanced settings toggle button from features tab in Yoast dashboard.
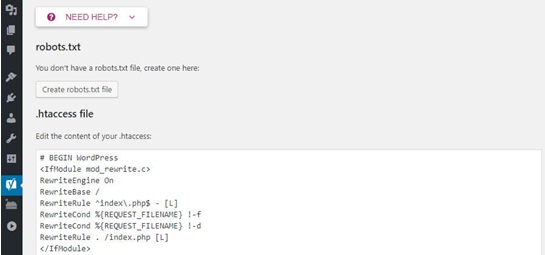
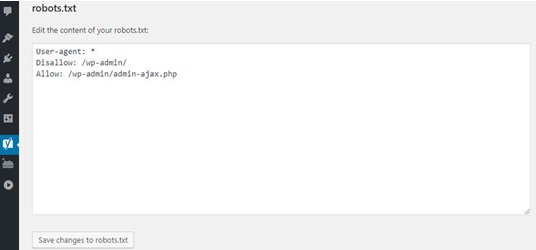
Step 2. Go to tools and then file editor. You will see .htaccess file and robots.txt creation button. Upon clicking “create robots.txt” an input text area will open where robots.txt file can be modified.
Step 3. Make sure to save any changes made to the robots.txt document to ensure retention of all the changes made.
Method 2. Through the All in One SEO Plug-in
Very similar to the above mentioned SEO plug-in, other than being a lighter and faster plug-in, creating a robots.txt file is also as easy in All in One SEO plug-in as it was in the Yoast SEO.
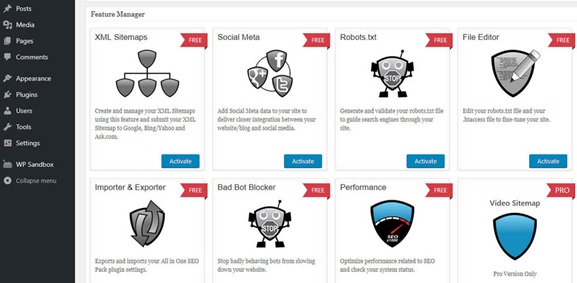
Step 1: Simply navigate to the All in One SEO and into the feature manager page on the dashboard.
Step 2: Inside, there is a tool which states robots.txt, with a bright activate button right under it.
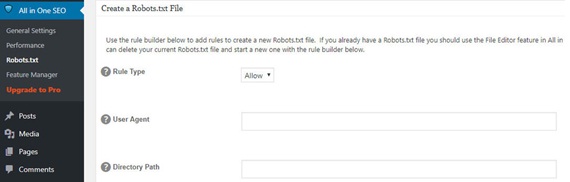
Step 3: A new robots.txt screen should pop up; clicking on it will allow you to add new rules, make changes or delete certain rules all together.
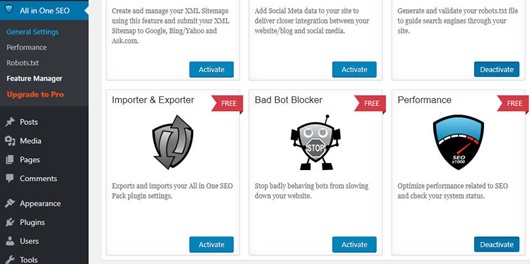
Step 4: All in one SEO also allows blocking of “bad bots” straight away via a plug-in.
Method 3. Create a new robots.txt file and upload it using FTP
Step 1: Creating a .txt file is one of the easiest things, simply open notepad and type in your desired commands.
Step 2: Save the file as .txt type
Step 3: Once a file has been created and saved, the website should be connected via FTP.
Step 4: Upon establishing FTP connection to the site
Step 5: Navigate to the public_html folder.
Step 6: All that is left to do is uploading the robots.txt file from your system onto the server.
Step 7: That can be done via simply dragging or dropping it or it can be done by right clicking on the file using the FTP client’s local
Testing in Google Search Console
1) Upon creation of robots.txt or on updating the robots.txt file, Google automatically updates robots.txt, alternatively it can also be submitted to the Google Search Console to test before you make changes to it.
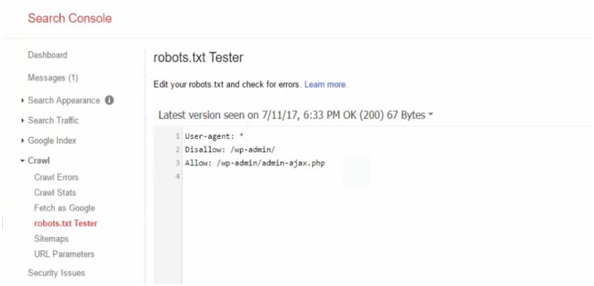
2) The Google Search Console is a collection of various tools provided by Google to monitor how the content will appear in the search.
3) In the search console we can observe an editor field where we can test our robots.txt.
4) The platform checks the file for any technical errors and in case of any; they will be pointed out for you.
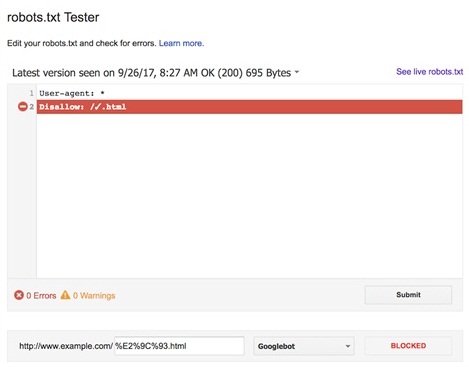
For the website to excel on a global level, one needs to make sure that the search engine bots are crawling only the important and relevant information.
A properly configured robots.txt will enable searchers and bots to access the domain’s best part and ensure a rise in the search engine rankings.
Error and warning reports related to robots.txt in Google Search Console
Regularly check for issues in coverage report in the Google Search Console regarding any robots.txt updates
Some Common Issues Are:-
Submitted URL blocked by robots.txt - This error is typically caused if an URL blocked by robots.txt is also present in your XML sitemap. Search Console shows it like this:
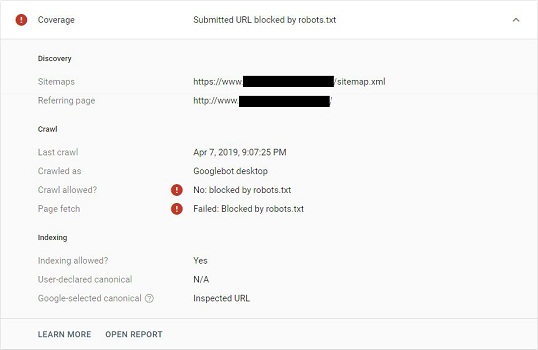
Solution #1 – Remove the blocked URL from the XML sitemap.
Solution #2 – - Check for any disallow rules within the robots.txt file and allow that particular URL or remove the disallow rule.
You can choose either solution depending on your priority and needs as to whether you want to block it or not.
-
Indexed, though blocked by robots.txt
This is a warning related to robots.txt which basically means you have accidentlly tried to exclude a page or resource from Google’s search results for which disallowing in robots.txt isn’t the correct solution. Google found it from other sources and indexed it.
Solution - Remove the crawl block and instead use a noindex meta robots tag or x robots-tag HTTP header to prevent indexing.
How to Manage Crawl Budget With robots.txt?
Crawl budget is an important SEO concept that is often neglected. It is the rate at which search engine’s crawlers go over the pages of your domain.
The crawl rate is “a tentative balance” between Googlebot’s desire to crawl a domain while ensuring the server is not being overcrowded.

Optimising Crawling Budgets with robots.txt
- Enable crawling of important pages in robots.txt.
- Within robots.txt disallow crawling of unnecessary pages and resources.
Bonus info:
Other Techniques to Optimise Crawl Budget :
- Keep an eye out for redirect chains.

- Use HTML as often as you can as majority of crawlers are still improving their indexing flash and XML.
- Make sure there are no HTTP errors (http:// links in the page which may be redirected to https:// version).
- 404 and 401 errors take up a huge chunk of a domains crawling budget. Don’t ever block a 404 URL, otherwise Search Engines will ever crawl it and will never know it’s a 404 page and needs to be deindexed.


- Unique URLs are accounted as separate pages and led to wastage of crawling budget.
- Keep your sitemaps updated, that makes it easier for internal links to be understood much faster and with ease by the crawlers.
<link rel="alternate" hreflang="lang_code" href="url_of_page" />should be included in the page’s header. As even though Google can find alternate language versions of any page, it is better to clearly indicate the language or region of specific pages to avoid wastage of crawling budget.
Meta Robot Tags vs robots.txt
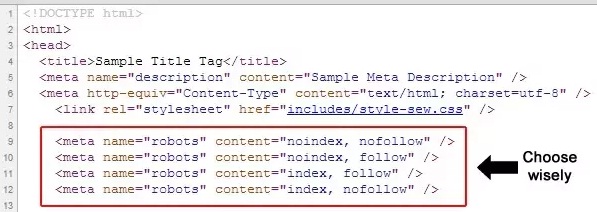
Meta robot tag provides extra functions which are very page specific in nature and can’t be implemented into a robots.txt file; robots.txt lets us control the crawling of web pages and resources by search engines. On the other hand, Meta robots lets us control the indexing of pages and crawling of link on the page. Meta tags are the most efficient when being used to disallow singular files or pages whereas robots.txt files work to its optimum capacity when being used to disallow sections of sites.
The difference between the two lies in how they function; robots.txt is the standard norm for communicating with crawlers and other bots and it helps set specific commands that guides crawlers to areas of the website that shouldn’t be crawled.
Meta robots tags are exactly what the name suggests, a tag. It guides the search engine like a crutch as to what to follow and what not to. Both can be used together as neither one has any sort of authority over the other.
The meta robots tag should be placed in the <head> section of the website and would look like: <meta name= “robots” content = “noindex”>
Most common meta robots parameters
- Follow:Every search engines is able to crawl through every internal link on the webpage. This signals the search engines that it can follow the links on the page in order to discover other pages.
Example:<meta name= “robots” content = “follow”>
Note: This is assumed by default on all pages – you generally won’t need to add this parameter. - No follow: It prevents the Google bots from following any links on the page.
Example:<meta name= “robots” content = “nofollow”>
Note: It’s unclear and highly inconsistent between the search engines whether this attribute prevents search engines from following links, or prevents them from assigning any value to those links. - Index: It allows search engines to add pages to their index, in order for it to be discovered by people who are searching for content similar to that being provided by you.
Example:<meta name= “robots” content = “index”>
Note: This is assumed by default on all pages – you generally won’t need to add this parameter. - No-Index: It disallows search engines from adding pages into their index’s, and as a result disallows them from showing it in search results.
<meta name= “robots” content = “noindex ”> - Noimageindex: Tells a crawler not to index any images on a page.
- Noarchive:Search engines should not show a cached link to this page on a SERP.
- Unavailable_after:Search engines should no longer index this page after a particular date. Reasons may inculde deletion, redirection etc.
Not To-Do in robots.txt File
- Block CSS, JavaScript and Image files: Blocking these contents in the robots.txt file cause harm as Google will not load the page completely. This means it is unable to see how the page looks like, what is the structure etc. Google may mark it as Not Mobile Friendly as critical resources are blocked by robots.txt and you will lose your rankings.
- Ignorantly using wildcards and de-indexing your site: For example you may want to block something but don’t exactly how the directives work and you end up blocking the whole site or important pages which may result in deindexing of your web pages or even whole site from Search Engines.
